Sound-Extraction
Audio-File Extraction
![]()
![]()

About
Use this tool to segment (i.e., clip or slice), copy, and extract short-duration recordings, from long-duration WAV or FLAC files. Segmenting audio files into smaller parts can make recordings compatible for certain analytical workflows and allow for easier manipulation and sharing. Segment and extracting recordings based on a list of recording start times (date times) and a desired duration. This allows for applications such as the extraction of stratified audio samples, among others.
There are two ways of installation and you only have to use one of them
1. Download the python package:
`pip install sound-extraction`
a. After the installation you can use the following command to run the program or use --help to see the arguments list:
sound_extraction -r "path/to/original/audio/files" -o "path/to/output/folder" -c "path/to/csv/file" -s "site_name"
and then you can follow the instructions for the arguments mentioned below to run the program. Python-Package
b. You can download the test files from the link and use the following command to run the program: Test Files
sound_extraction -r "/path/to/original/audio/files" -o "/path/to/output/folder" -c "/path/to/csv/file" -s "site_name"
OR
2. If you want to run the program from the source files then follow the steps below: Source-File.
git clone https://github.com/prayagnshah/Sound-Extraction.git
Note: You can use any one of the installation above to run the program.
Setup (Windows)
Download Audio-File Extraction Files: Sound-File Extraction
python -m venv venv
venv\Scripts\Activate
pip install -r requirements.txt
If creating virtual environment gives us an error then open the Powershell with administrator and run the following command:
Set-ExecutionPolicy Unrestricted
Setup (Linux)
Download Audio-File Extraction Files: Sound-File Extraction
python -m venv venv
source venv/bin/activate
pip install -r requirements.txt
Usage
-
Run sound_extraction.py to get the extracted audio files. You need to set the working directory where the downloaded files are located. Here is an example:
python sound_extraction.py -r "path/to/original/audio/files" -o "path/to/output/folder" -c "path/to/csv/file" -s "site_name"
Arguments and commands used are required to get the extraction of audio files according to the sample times. After entering the argument users will be asked to enter the custom sub-directory nameto store the extracted audio files. If you don’t want to enter the custom name then just press Enter and it will extract the audio files in the same output directory mentioned in the argument.
-
Run sound_extraction.py to get the sliced audio files which can handle around 192K sample rate. Here is an example:
python sound_extraction.py -r "path/to/original/audio/files" -o "path/to/output/folder" -slice 10
Arguments and commands used are required to get the slicing of larger audio files into smaller audio files of your choice.
Arguments
Here’s a complete list of all command line arguments:
-r, Path to original audio files (required). Need to make sure all the audio files are stored in a folder.
-o, Path to output folder (required). Program will create a folder for you with current time, name of site and extraction of duration to the specified path.
-c, Path to the CSV file with the following requirements: Header should include "sample file" and "category" columns. The "sample file" column should be in the format 20220608_170343, and the "category" column should contain categories such as "Nocturnal", etc.
-s, Prefix or the recording name, or ID, etc. This will be used to name the extracted audio files.
-d, Duration of the extracted audio file. Change the duration of the extracted audio files, if required. Default is 3 minutes.
-span, Span of the audio file. Extracted audio files will not span to 3 minutes if the original file is shorter.
-e, Extension of the audio file (.wav or .flac). If your original audio files are flac then you need to use ".wav". Default is flac.
-slice, Slice the audio file in smaller segments/chunks. Default is 10 seconds.
We can see the arguments list by using the following command:
python sound_extraction.py -h
-
This is very basic version of the analysis of the workflow, you can adjust it to your needs.
-
All the unusual files are handled and will show in console as a log message.
-
Please open an issue if you have any questions or suggestions to add any features.
-
I will keep on updating the code and making it more efficient.
Test Files Usage
Download Test Files: Test Files
python sound_extraction.py -r "/path/to/original/audio/files" -o "/path/to/output/folder" -c "/path/to/csv/file" -s "site_name"
Error Handling
-
Log file will be created in the output folder with the name of
sound_extraction_logs.txtwhich will show all the corrupted files which happened during the extraction process. -
This program will send the error message to the Sentry server to improve the user performace and to keep track of the errors which will be handled by myself.
Important Notes
-
Try to have your original audio files in subfolder of root directory and once you provide path of root folder then code will search for all the files in all subfolders as well as in root folder.
-
Original files should be in the format
20220611T202300.wavor20220611T202300.flac. Sample files in CSV should be in the format20220611_202300.wavor20220611_202300.flacunder the headingsampleFile. For instance,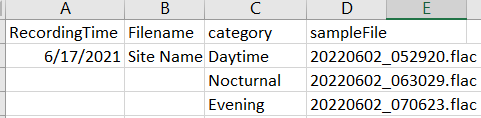
-
If you do not have the CSV file with sample times then you can generate the CSV file by following this README
Changelog
- All the version changes are mentioned in the CHANGELOG.md file.
Contributing
Contributions are welcomed and appreciated. Here are some ways to get involved: * Submitting bug reports. * Feature requests or suggestions. * Improving the documentation or providing examples. * Writing code to add optimizations or new features.
Please use the GitHub issue tracker to raise any bugs or to submit feature requests. If something does not work as you might expect, please let us know. If there are features that you feel are missing, please let us know.
Code submissions should be submitted as a pull request.
If you are stuck or need help, raising an issue is a good place to start. This helps us keep common issues in public view.
Please note that we adhere to code of conduct
Research Paper
If you want to find how we are using this tool in our research then you can read our paper: Research-Paper